
Результатом активного медіаспоживання з використанням соціальних мереж стали все більш кричущі випадки маніпуляції думкою користувачів. Саме тому StopFake розпочинає серію публікацій про інструменти, які допомагають боротися зі впливом алгоритмів соціальних сервісів на споживаний нами контент. Ми навмисно не будемо пропонувати нашим читачам найбільш радикальний метод – видалення профайлів у соціальних мережах, бо розуміємо, що за нинішніх умов це може бути нереально. Крім того, соціальні мережі є важливою платформою для роботи фактчекерів, громадських журналістів і активістів. Але ми навчимо вас краще розуміти, що і чому ми бачимо у своїй стрічці Facebook або Twitter (і чого не бачимо) й розповімо про інструменти, які дають змогу максимально звести нанівець вплив алгоритмів соціальних мереж на контент, який відображається ними.
Cambridge Analytica і 87 мільйонів жертв
Назва компанії Cambridge Analytica, що вперше з’явилася в медіа ще в 2016 році, у квітні 2018 року буквально підірвала медіапростір. Відразу в декількох публікаціях розповідалося про те, як дослідницька компанія Cambridge Analytica ще в 2015 році отримала доступ до 50 мільйонів профайлів користувачів соціальної мережі Facebook (пізніше стало відомо, що їхня кількість насправді перевищує 87 млн).
Частина даних була отримана після того, як користувачі за гроші пройшли психологічний тест, створений ученим-психологом, який і передав отриману інформацію в Cambridge Analytica.
На основі даних цих профайлів компанія навчилася формувати і демонструвати персоналізовану рекламу, яка не тільки сприяла перемозі Дональда Трампа на виборах у США, але ще тією чи іншою мірою вплинула на результати більше 200 виборчих процесів у різних країнах світу.
Ці публікації викликали ефект бомби, що розірвалася. Акції Facebook обвалилися, глава компанії Марк Цукерберг був викликаний для надання свідчень до Конгресу США. Можна по-різному оцінювати і дивні питання конгресменів, які не завжди уявляють собі, як працює Facebook і сучасний інтернет. Але відповіді Цукерберга і увага до цієї історії стали демонстрацією того, як уперше в сучасній історії суспільство (та й сам глава найбільшої соціальної мережі) задумалося над тим, який вплив Facebook і базові принципи його роботи чинять на різні аспекти життя, в тому числі й на результати політичного волевиявлення людей у всьому світі.
Facebook повідомив про цілу низку змін, про які ми розповімо пізніше. І поки будуть відбуватися подальші розслідування і дослідження впливу Facebook, звичайним користувачам варто замислитися про свою Facebook-залежність і над тим, як сильно впливає Facebook і його дочірні проекти на наше медіаспоживання.
Перше, що запропонував Facebook після публікації історії з Cambridge Analytica, стала можливість перевірити себе – чи не стали ви жертвами компанії Cambridge Analytica та її застосування, яке отримало несанкціонований доступ до даних.
Щоб виконати цю перевірку, потрібно скористатися ось цим посиланням.
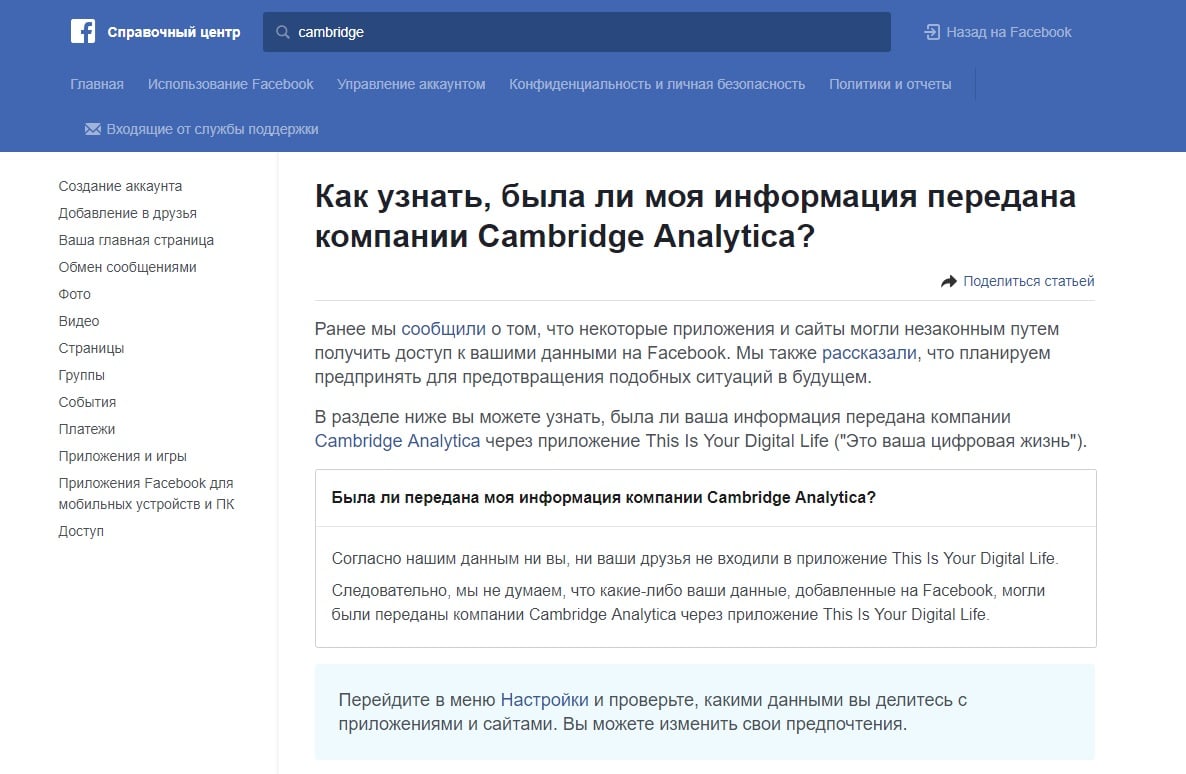
На відповідній сторінці довідкового розділу Facebook можна знайти відповідь на те, чи пов’язані ви і ваші друзі з додатками Cambridge Analytica, а також пропозицію перевірити налаштування свого Facebook-акаунта і під’єднаних до нього додатків.
Для цього можна скористатися або посиланням на сторінці допомоги, або перейти в налаштування свого Facebook-акаунта, а там — до розділу додатків.
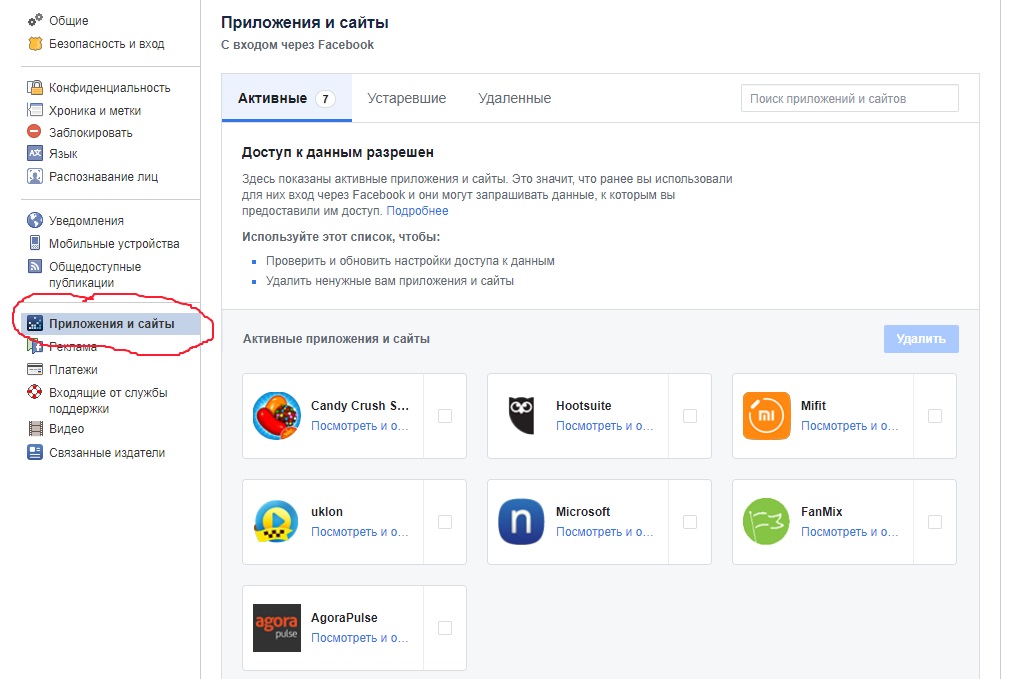
Якщо на цій сторінці ви побачите дивні програми, або незнайомі, або рідко використовувані — їх краще відразу видалити.
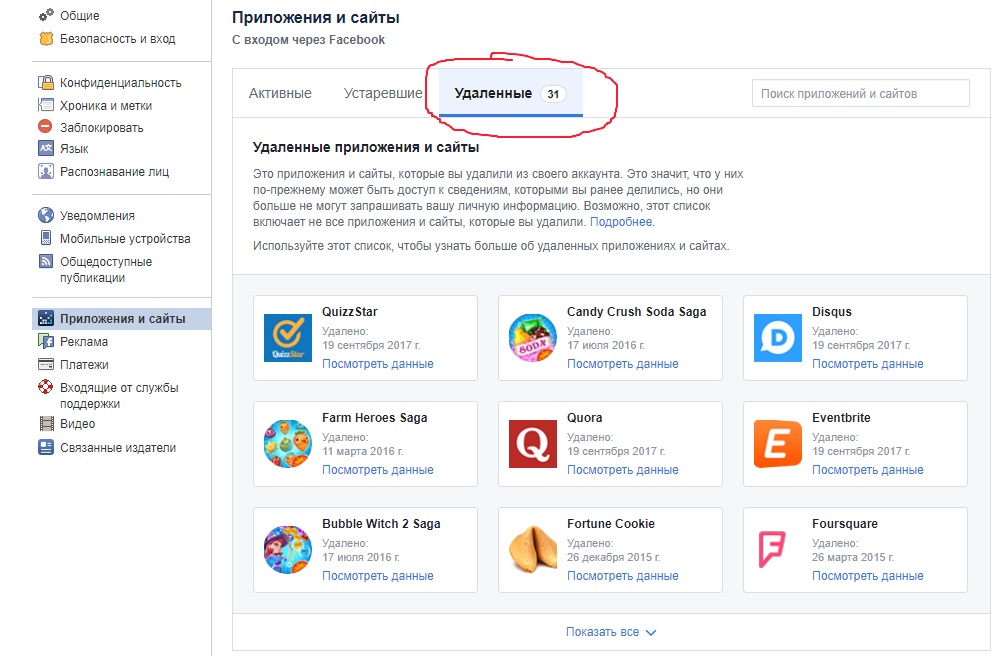
У Facebook підкреслюють, що небезпечними можуть бути і раніше встановлені програми. Їх теж варто перевірити.
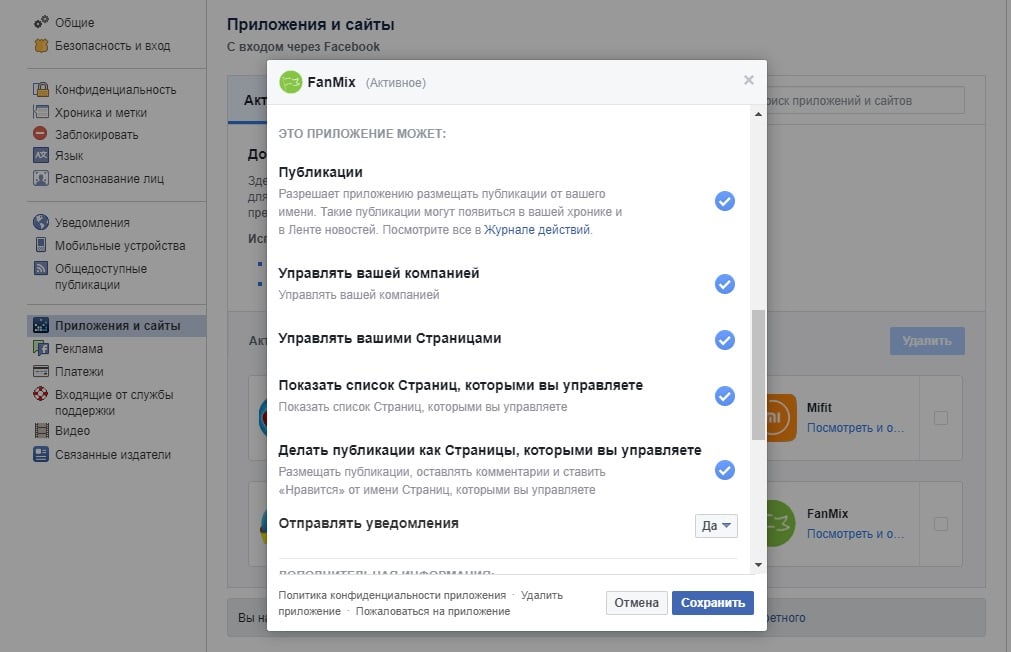
Для кожної програми можна побачити, які саме дозволи у неї є і які дії додаток може здійснювати. Якщо у якогось додатку виявиться занадто багато прав, варто видалити і його – зробити це можна за допомогою кнопок у вікні налаштувань.
Корисний або маніпулятивний? Що і чому ми бачимо в соцмережах
Соціальні мережі зберігають дуже багато інформації про своїх користувачів і використовують ці дані для демонстрації реклами. Сутнісно бізнес-модель соціальних сервісів побудована на тому, що вони продають дані про користувачів рекламодавцям, щоб ті показували таргетовану рекламу – таку, яка буде цікава конкретному користувачеві. Завдяки такій моделі молода мама бачить рекламу підгузників і крамниць дитячого одягу, людина, що цікавиться спортом – рекламу марафонських забігів і спортивного харчування, а випускник школи – рекламу університетів і курсів з підготування до ЗНО.
Проблема в тому, що крім інформації, яку ми самі «віддаємо» Facebook, заповнюючи свій профайл або вказуючи відвідувані місця і заходи, алгоритми соціальної мережі навчилися аналізувати наші профайли і наші дії – як усередині соціальної мережі, так і поза нею. І в результаті це призвело до того, що Facebook знає близько сотні характеристик своїх користувачів, на основі яких він може показувати рекламу. Серед цих характеристик – навіть такі дивні, як бажаний стиль відпочинку, наявність і тип автомобіля, використання купонів і кількість кредитних карт.
Соціальні мережі вміють збирати інформацію про дії користувачів не тільки безпосередньо на їхніх сторінках, а й на інших сайтах. Цьому сприяють такі механізми, як cookies-файли, Facebook Pixel, авторизація на сайтах через соцмережі. У результаті цього соцмережі не тільки демонструють своїм користувачам цікавий їм контент. Деякі медіа вже вміють налаштовувати свої головні сторінки залежно від інтересів і потреб користувачів. Отож, ми стикаємося з більш глобальним проявом «міхура фільтрів», але не щодо пошукових результатів, а щодо контенту соціальних мереж і онлайн-медіа.
Facebook Container від Mozilla
Щоб отримати максимально незалежний контент, для читання новин можна скористатися окремим браузером, у якому не потрібно авторизуватися в соцмережах.
Ще один спосіб розв’язати це завдання – встановити цілком новий плагін Facebook Container, створений командою розробників з компанії Mozilla. Плагін поки існує тільки для браузера Firefox. Він з’явився зовсім недавно, можливо, як відповідь на історію з Cambridge Analytica. Завдання плагіна – максимально ускладнити для соціальних мереж відстеження онлайн-поведінки людини на зовнішніх сайтах. Іншими словами, Facebook Container перешкоджає стеженню за користувачем з боку соціальних мереж, а, значить, сприяє більш незалежному медіаспоживанню людини.
Facebook Container створює умовний контейнер для роботи в Facebook. У цьому контейнері використовуються власні cookies-файли. Ці cookies-файли не передаються поза Facebook, отже, соцмережа не може «бачити», що робить користувач на інших сайтах. А інші сайти не можуть розпізнати своїх відвідувачів як Facebook-користувачів.
Після встановлення Facebook Container у браузер Firefox поруч з адресним рядком при перегляді Facebook-стрічки або Facebook-сторінок буде відображена спеціальна блакитна позначка («Контейнер»). Усі інші популярні сторінки завантажуватимуться поза контейнером. Таким способом Facebook Container моделює ситуацію, в якій Facebook та інші сайти нібито використовуються в різних браузерах.
Щоправда, слід розуміти, що інші рекламні мережі — та ж реклама від Google — може намагатися ідентифікувати користувача і «підсовувати» йому цікавий для нього контент.
Як позбутися від курування контенту, або Згадаймо про RSS
Алгоритмічні стрічки Facebook та інших сервісів стали одним з варіантів прояву курування контенту – відбору і надання контенту в зручному і цікавому для користувача вигляді. Поява поняття курування контенту пов’язана з величезною кількістю записів у соціальних мережах, неможливістю стежити і сприймати їх усі й, звичайно ж, бажанням компаній, які володіють соцмережами, заробляти на призначених для користувача перевагах.
Завдяки куруванню контенту (використовуваному не тільки в соцмережах, а й у деяких онлайн-медіа) звичайна стрічка новин, сформована в зворотному хронологічному порядку, залишилася в минулому.
З одного боку, курування контенту покликане зробити наше медіаспоживання зручнішим, з другого — ми платимо за це нашими персональними даними та «делегованим» вибором того, що ми бачимо на своїх екранах.
Історія з Cambridge Analytica може стати хорошим приводом згадати про формат RSS та інструменти читання новин через RSS. Цей спосіб споживання контенту був популярним у 2008-2012 роках. Але поява Facebook і закриття сервісу Google Reader призвели до масової відмови від роботи з RSS-форматом і до читання новин через Facebook.
Однак RSS-формат якраз і виключає всі недоліки споживання новин через Facebook — він не збирає призначені для користувача дані й не налаштовує контент, який бачать користувачі. Ба більше, спеціальні інструменти для читання RSS уміють зібрати на одній веб-сторінці записи з усіх джерел, які потрібні користувачеві, згрупувати їх у категорії та переглядати, як мінімум, заголовки, або повні тексти новин. Завдяки RSS-рідеру не потрібно відкривати кожну окрему сторінку, аби прочитати новини, миритися з рекламними банерами і повідомленнями, що виринають.
RSS розшифровується по-різному — це і RDF Site Summary, і Really Simple Syndication, і Rich Site Summary. Іншими словами, RSS можна перекласти як «винятково просте поширення інформації». Термін «синдикація» позначає багаторазове публікування новини або статті в декількох джерелах.
Читати RSS можна на спеціальних сайтах, за допомогою спеціальних програм, званих ще агрегаторами, або онлайнових сервісів для читання RSS.
У формату RSS є недоліки – аби таким способом можна було читати новини, потрібно, щоб сайт пропонував цей формат. Дізнатися, чи є у сайту RSS-фід і чи можна читати його новини через RSS, допоможуть спеціальні онлайн-сервіси – RSS-агрегатори.
Ось кілька таких сервісів: Veen Reader, Feedly https://feedly.com , The old reader
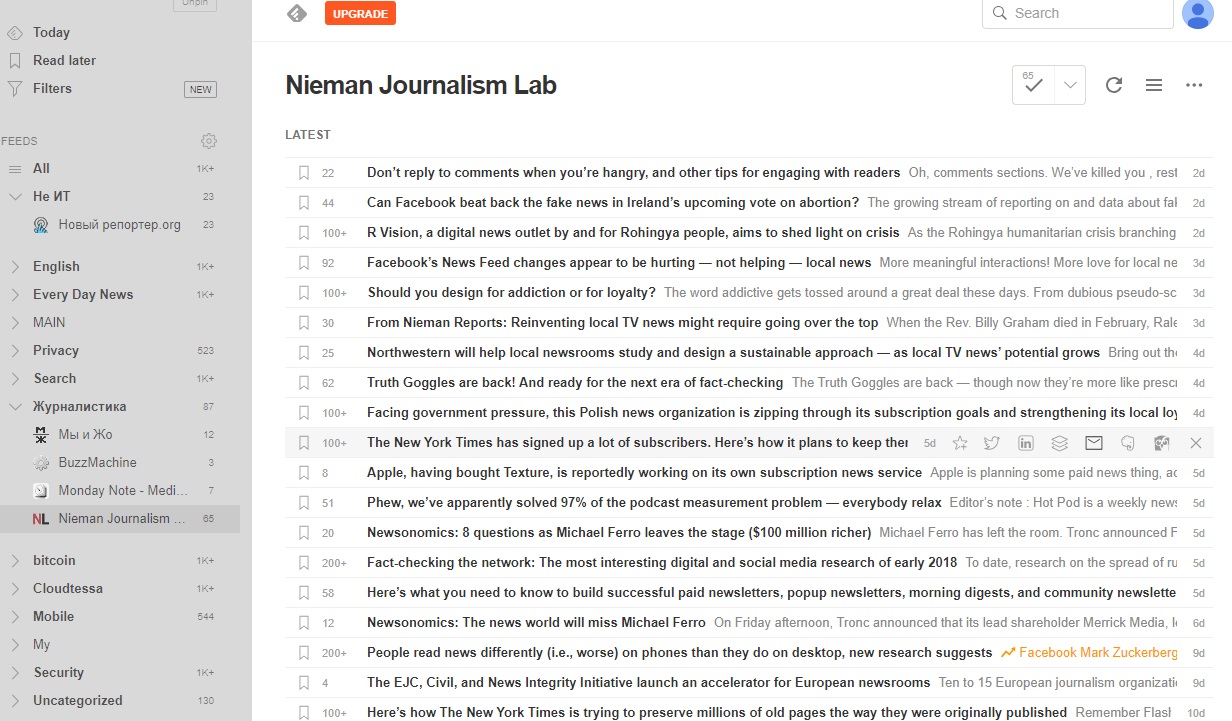
Наприклад, щоб додати сайт для читання в сервіс Feedly, потрібно скористатися кнопкою Add Content, вибрати пункт Publications & Blogs і вказати адресу сайту. Якщо у сайту є RSS-фід, сервіс Feedly запропонує додати його до свого переліку читання.
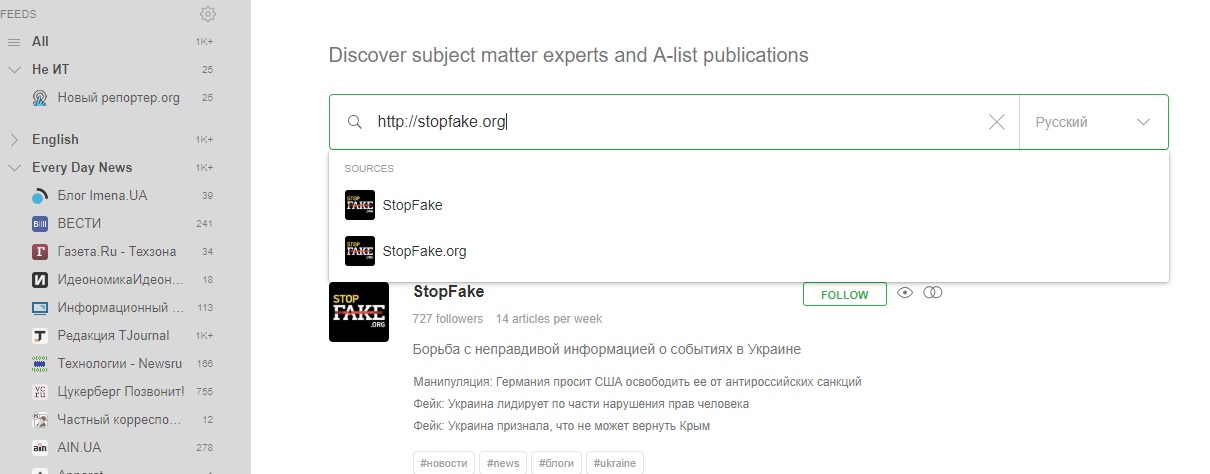
У наступних публікаціях розділу «Інструменти» ми розповімо про інші сервіси і плагіни, що їх завдання – позбутися від упливу алгоритмів соцмереж на те, що і як ми читаємо онлайн.
Автор: Надія Баловсяк, для Stopfake.org.


